"Do it! 쉽게 배우는 R 데이터 분석"
책을 참고하여 R을 공부했으며, 글을 작성했습니다.
☑️ 한국복지패널데이터 분석
🔍 데이터 준비
# install.packages("foreign")
library(foreign) # SPSS 파일 불러오기
library(dplyr) # 전처리
library(ggplot2)# 시각화
library(readxl) # 엑셀 파일 불러오기
🔍 데이터 불러오기
raw_data <- read.spss("./data/Koweps_hpc10_2015_beta1.sav", to.data.frame = T) # 데이터 불러오기
data <- raw_data
# 데이터 전처리 과정 중에 데이터에 문제가 생기면 여기서부터 다시 시작 (= 백업파일)
🔍 변수명 변경

# 변수 이름 변경
welfare <- rename(welfare,
sex = h10_g3,
birth_year = h10_g4,
marital_status = h10_g10,
religion = h10_g11,
job_code = h10_eco9,
income = p1002_8aq1,
region = h10_reg7)
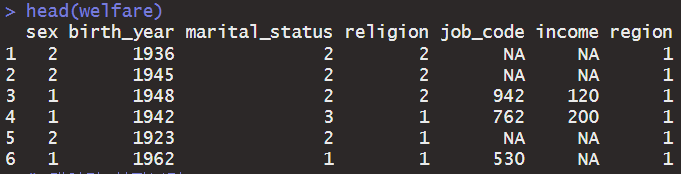
분석에 사용할 변수들을 보기 편하게 변경을 진행하였다.
☑️ 실습 1. 성별에 따른 월급 차이
1) 변수 검토 및 전처리 2) 변수 간 관계분석
1) 변수 검토 및 전처리 : 성별 변수 검토
범주형 변수 = 빈도
# 이상치 판단
table(welfare$sex)

이상치 없음
# 결측치 판단
table(is.na(welfare$sex))
성별 변수를 범주형 변수로 변환
welfare$sex <- ifelse(welfare$sex == 1, "Male", "Female")

성별값이 1 일 땐 Male , 1이 아닐 땐 Female로 변환
1) 변수 검토 및 전처리 : 월급 변수 검토
연속형 변수 = 요약통계
# 이상치 판단
summary(welfare$income)

이상치는 월급이 없는 사람
0 이라는 값을 가진 사람 제외 => 결측치 NA로 변경해야 함
# 결측치 판단
table(is.na(welfare$income))

현재 결측치 12030개
# 0인 값도 결측치로 변경
welfare$income <- ifelse(welfare$income == 0, NA, welfare$income)
table(is.na(welfare$income))
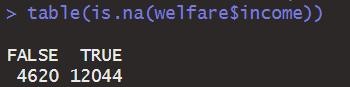
현재 결측치 12044개 = 14개 추가된 것을 확인 가능
2) 변수 간 관계분석 : 성별에 따른 월급 평균값 데이터가 필요
sex_income <- welfare %>%
filter(!is.na(income)) %>%
group_by(sex) %>%
summarise(income_mean = mean(income))


남자가 여자보다 평균적인 월급이 더 높은 결과가 나타났다.
그러나 통계적으로 유의미한 차이가 있는지 통계분석을 실시하는것이 바람직하다.
독립표본 t검정, 등분산 가정
sex_income_t <- welfare %>%
filter(!is.na(income))
t.test(sex_income_t$income ~ sex_income_t$sex, var.equal = T)

p-value가 0.05보다 작으므로 두 그룹 간의 유의한 차이가 있다
결론: 성별에 따른 월급은 통계적으로 유의한 차이가 있다
'데이터분석 찍어먹기 > R' 카테고리의 다른 글
| 5일차 - 데이터 다뤄보기[그래프_8장] (1) | 2024.07.19 |
|---|---|
| 4일차 - 데이터 다뤄보기 [정제-7장] (0) | 2024.07.18 |
| 3일차 - 데이터 다뤄보기 [가공_6장] (0) | 2024.07.12 |
| 2일차 - R 데이터 다뤄보기 [기초_1장] (0) | 2024.07.10 |
| 1일차 - R 이랑 친해지기 [1-4장] (0) | 2024.07.05 |



