"Do it! 쉽게 배우는 R 데이터 분석"
책을 참고하여 R을 공부했으며, 글을 작성했습니다.
☑️R 이란?
데이터 분석가들이 가장 많이 사용하는 데이터 분석 전문 도구이며, 데이터를 분석하는 데 사용되는 소프트웨어(IDE)
어디에 주로 사용될까?
통계분석, 머신러닝 모델링, 텍스트 마이닝, 소셜 네트워크 분석, 지도 시각화, 주식 분석, 이미지 분석, 소리 분석 등
R 의 장점은 무엇일까?
무료로 사용할 수 있는 오픈소스, 다양한 그래프와 교육자료, 전문적인 데이터 분석
☑️R 준비
1. 공식홈페이지에서 설치를 완료하였으며, 버전은 최신버전보다 조금 아래버전인 4.3.0을 설치했다.

2. 프로젝트 만들기
아래 그림과 같이 프로젝트 파일을 생성
주의 : 프로젝트 이름과 경로에 "한글" 이 들어가면 오류가 발생할 수 있으니 주의해야 한다.

3. 파일(스크립트) 및 소스코드 창 생성

이제 R 설치 및 기초까지 마쳤고, 다른 설정까지도 마쳤으니 이제 본격적으로 R 시작!!
☑️R 실행
변수와 상수
변수(변하는 값) : 데이터분석의 대상
상수(고정) : 데이터분석의 대상이 아님
하나의 변수 선언 ( <-)
파이썬과 다른 점이 존재
a <- 1 # R
a = 1 # Python
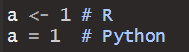
R은 기존 Python과 다르게 <- 로 변수를 할당하게 된다.
여러 변수 선언
파이썬과 다르게 여러 개의 변수를 선언할 땐 c() 사용
combine 함수: 여러 개의 값을 저장
v <- c(1,5,7,9,2)
v

또한 c에서는 연속적인 값을 저장할 수 있는데, 아래와 같이 슬라이싱을 사용할 수 있다.
v2 <- c(1:5)
v2

중요한 점 : 슬라이싱
R : (끝번호 포함O포함 O) (1:5) -> 1,2,3,4,5
Python : (끝번호 포함X포함 X) (1:5) -> 1,2,3,4
R 에선 끝번호도 포함한다는 사실을 꼭 잊지 말자
sequence 함수
c()를 사용하지 않고, 연속적인 숫자 값을 저장
특정 규칙에 따라 연속적인 값을 저장
v3 <- seq(1,5)
v3

위에서 c() + 슬라이싱을 사용한 결과와 seq()의 결과가 같다는 것을 알 수 있다.
v4 <- seq(0,10, by=2)
v4
v5 <- seq(1,10, by=2)
v5

by를 사용하여 숫자의 간격을 설정하여 홀수와 짝수와 같은 특정규칙의 연속적인 값도 저장이 가능하다.
문자 변수 선언
문자 변수도 숫자와 마찬가지로 c()를 사용하면 된다.
변수와 문자도 합칠 수 있으며, paste와 collapse옵션을 사용하면 문자끼리 합칠 수 있다.
str4 <- c("Hello!", "World", "is", "good!")
str4
paste("Hello!", "World", "is", "good!") # 1
paste(str4, collapse = " ") # 2
str4에 문자열을 각각 저장하고, 문자열을 합치기 위해서 paste를 사용
#1 : 문자열 각각 나열하여 paste
#2 : 저장된 문자열과 collapse를 사용하여 paste

collapse의 기본값은 띄어쓰기인데, 띄어쓰기 없이 합치고 싶다면 paste0를 사용하면 된다.
paste0("Hello!","World","is","good!") # 블랭크 없이 합치는 옵션

파일 가져오기 및 조건
파이썬과 동일하게
read.csv를 활용하여 파일을 불러올 수 있다.
그러나 여기서 주목할 점은 pattern 이란 건데,
list.files(path, full.names = TRUE, pattern = "csv_exam")

pattern을 사용하여 찾고 싶은 단어를 입력하면, 입력한 단어가 포함되어 있는 파일들의 리스트를 보여주게 된다.
요약통계량
연속형 변수에 해당되며, 박스플롯과 분석에 용이한 통계량이다.
example <- read.csv("./data/csv_exam.csv")
summary(example)

이런 식으로 최솟값, 1분위수, 중앙값(=2분위수), 3분위수, 최댓값(=4분위수)이 나오게 된다.
상관계수 = cor(a,b)
data1 <- c(45,56,34,56,25,74,35,68,98,56)
data2 <- c(7,5,3,6,4,7,6,4,5,9)
# correlation
cor(data1,data2)
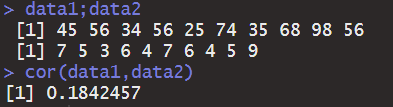
두 변수에 대해서 상관계수를 구하는것은 추후 통계분석에 있어서 필수불가결한 정보이므로 꼭 기억해둬야 할 코드이다.
'데이터분석 찍어먹기 > R' 카테고리의 다른 글
| 6일차 - 데이터 분석 [실습_9장] (0) | 2024.07.24 |
|---|---|
| 5일차 - 데이터 다뤄보기[그래프_8장] (1) | 2024.07.19 |
| 4일차 - 데이터 다뤄보기 [정제-7장] (0) | 2024.07.18 |
| 3일차 - 데이터 다뤄보기 [가공_6장] (0) | 2024.07.12 |
| 2일차 - R 데이터 다뤄보기 [기초_1장] (0) | 2024.07.10 |



