"Do it! 쉽게 배우는 R 데이터 분석"
책을 참고하여 R을 공부했으며, 글을 작성했습니다.
☑️데이터 가공
🔍 파이프라인
%>%
"파이프 연산자"라고 불리며, 수도관처럼 함수들을 연결하는 기능을 한다.
단축키 : ctrl + shift + m
🔍 데이터 전처리
| 함수명 | 특징 |
| 1. filter() | 행 추출 |
| 2. select() | 열 (변수)추출 |
| 3. arrange() | 정렬 |
| 4. mutate() | 변수 추가 = 파생변수 |
| 5. group_by() | 집단별로 나누기 |
| 6. summarise() | 통계치 산출 |
| 7. left_join() | 데이터 합치기(열) / 가로 = 열 + 열 = cbind |
| 8.bind_rows() | 데이터 합치기(행) / 세로 = 행 + 행 = rbind |
유의할 점 : group_by 와 summarise는 항상 같이 많이 쓴다
🔍 데이터 추출
%in%
% in% : 변수의 값이 지정한 조건목록에 해당하는지 확인하는 기능
%in% + c() 함수
# 조건에 맞는 행을 데이터로 저장
class135 <- exam %>%
filter(class == 1 | class == 3 | class == 5)
class135

변수제외
특정 변수를 제외하고 싶을 때 변수명 앞에 - 붙여서 사용
# 특정 변수 제외
exam %>%
select(-math)

혼자서해보기 P.133
자동차 제조 회사에 따라 도시 연비가 다른지 알아보려고 합니다.
"audi"와 "toyota" 중 어느 manufacturer(자동차 제조 회사)의 cty(도시 연비)가 평균적으로 더 높은지 알아보세요.
#
audi_cty <- mpg %>% # 데이터 부르고 파이프라인
filter(manufacturer == "audi")
toyota_cty <- mpg %>%
filter(manufacturer == "toyota")
mean(audi_cty$cty)
mean(toyota_cty$cty)

Toyota 회사가 Audi 회사보다 평균 연비가 더 높은 것으로 확인된다.
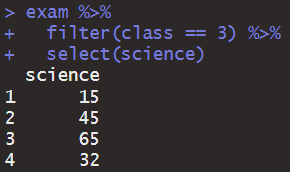
행과 열을 동시에 추출(filter와 select 동시에 사용)
# 행과 열을 동시에 추출하여 저장
class3_science <- exam %>%
filter(class == 3) %>%
dplyr::select(science)
class3_science
🔍 데이터 정렬
오름차순 정렬
# 오름차순 정렬
exam %>%
arrange(math)

내림차순 정렬
# 내림차순 정렬
exam %>%
arrange(desc(math))

🔍 파생변수 추가
mutate()
기존 데이터에 파생변수를 만들어 추가할 수 있다.
새로 만들 변수명과 변수를 만들 때 사용할 공식을 입력하면 된다.
exam %>%
mutate(total = math + english + sc ience)

mutate() + ifelse()
조건에 따라 다른 값을 부여한 변수를 추가할 수 있다.
❗ 유용하게 쓰일 수 있어서 꼭 알아두어야 할 코드이다 ❗
exam %>%
mutate(math_test = ifelse(math >= 80, "pass", "fail"))

🔍 데이터 요약
summarise() + group_by()
집단별 평균 및 요약한 값을 구하려고 할 때 사용되며, 여러 요약통계량값을 사용할 수 있다.
# 집단별로 요약하기
exam %>%
group_by(class) %>%
summarise(mean_math = mean(math))

# 각 집단별로 다시 집단 나누기
mpg %>%
group_by(manufacturer, drv) %>%
summarise(mean_cty = mean(cty))%>%
head(10)

🔍 데이터 합치기
left_join
# 가로로 합치기
total <- left_join(data1, data2, by = "id")

bind_rows
# 세로로 합치기
group_all <- bind_rows(data1, data2)

merge
# 교집합으로 합치기
data <- merge(data1, data2, by = "id")

'데이터분석 찍어먹기 > R' 카테고리의 다른 글
| 6일차 - 데이터 분석 [실습_9장] (0) | 2024.07.24 |
|---|---|
| 5일차 - 데이터 다뤄보기[그래프_8장] (1) | 2024.07.19 |
| 4일차 - 데이터 다뤄보기 [정제-7장] (0) | 2024.07.18 |
| 2일차 - R 데이터 다뤄보기 [기초_1장] (0) | 2024.07.10 |
| 1일차 - R 이랑 친해지기 [1-4장] (0) | 2024.07.05 |



